Przegląd bibliotek#
Autor sekcji: dr Filip Wójcik
Python jest jednym z najczęściej wybieranych języków programowania w zastosowaniach analitycznych. Swoją pozycję zawdzięcza między innymi:
Relatywnej łatwości nauki;
Dużej ilości dostępnych bibliotek;
Aktywnej społeczności;
Wykorzystaniu przez różne grupy zawodowe: od testerów, administratorów, po programistów i analityków danych.
Nic więc dziwnego, że jest uznawany za wiodące rozwiązanie w dziedzinie Data Science.
Istnieje cała masa bibliotek przeznaczonych do rozmaitych zastosowań, nierzadko dublujących się lub będących „nakładkami” na inne narzędzia. W tej sekcji zostaną przedstawione najważniejsze, naszym zdaniem, biblioteki, które warto znać i umieć wykorzystać w codziennej pracy.
Dla ułatwienia zadania podzieliliśmy je na kilka kategorii:
Biblioteki do analizy danych;
Biblioteki do operacji matematycznych i statystycznych;
Biblioteki do wizualizacji danych;
Biblioteki do uczenia maszynowego;
Biblioteki do analizy szeregów czasowych;
Biblioteki do automatyzacji i optymalizacji pracy;
Inne.
Lista ta oczywiście nie jest w pełni kompletna i nie obejmuje m. in. narzędzi z zakresu np. MLOps, czyli zarządzania cyklem życia modeli uczenia maszynowego oraz całych projektów. Dodatkowo, niemal każda pod-dziedzina uczenia maszynowego posiada własne zestawy specyficznych bibliotek, których są dziesiątki. Przykładowo:
Dla analizy grafów i grafowych sieci neuronowych:
Dla analizy języka naturalnego i przetwarzania tekstu:
Transformers od Hugginface - cały zestaw powiązanych narzędzi dla modeli LLM i szkolenia modeli językowych.
Dla analizy obrazów:
i tak dalej. Pracując z konkretną pod-dziedziną musimy zapoznać się z konkretnymi narzędziami w niej używanymi.
Lista zamieszczona w tej sekcji zawiera tylko absolutne minimum przydatne każdemu, rozpoczynającemu swoją przygodę w świecie DS.
Biblioteki do pracy z danymi#
Praca z danymi jest kluczowym elementem Data Science. Poniżej przedstawiamy dwie popularne biblioteki do manipulacji i analizy danych: pandas oraz polars.
Pandas#
Pandas to jedna z najbardziej wszechstronnych bibliotek Pythona, używana do manipulacji i analizy danych. Oferuje elastyczne struktury danych, takie jak Series (jednowymiarowe tablice) i DataFrame (dwuwymiarowe tablice/tabele bazodanowe/arkusze Excel - ogólniej: dane ustrukturyzowane).
Pandas jest nieodzownym elementem w zestawie narzędzi Data Science.
Zastosowania Pandas
Pandas jest używany do:
Ładowania, czyszczenia i przekształcania danych.
Analizy danych, takich jak grupowanie, agregacja, filtrowanie.
Pracy z danymi z plików CSV, Excel, baz danych, oraz formatów takich jak JSON.
Dodatkowe materiały#
Przydatne linki - Pandas
Książka - Data analytics with Python pokrywająca dużą część funkcjonalności biblioteki Pandas.
Przykład 1: Proste wczytywanie danych z pliku CSV#
import pandas as pd
# Wczytywanie danych z pliku CSV
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/titanic.csv"
titanic_data = pd.read_csv(url)
# Przegląd pierwszych kilku wierszy
titanic_data.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
# Generowanie podsumowania danych
print(titanic_data.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 class 891 non-null object
9 who 891 non-null object
10 adult_male 891 non-null bool
11 deck 203 non-null object
12 embark_town 889 non-null object
13 alive 891 non-null object
14 alone 891 non-null bool
dtypes: bool(2), float64(2), int64(4), object(7)
memory usage: 92.4+ KB
None
W powyższym przykładzie załadowano dane dotyczące pasażerów Titanica z pliku CSV dostępnego online, a następnie wyświetlono pierwsze kilka wierszy oraz podstawowe informacje o zbiorze danych, takie jak liczba wierszy i kolumn oraz typy danych.
Przykład 2: Filtrowanie i grupowanie#
# Filtrowanie danych - tylko kobiety, które przeżyły
surviving_females = titanic_data[(titanic_data['sex'] == 'female') & (titanic_data['survived'] == 1)]
print("Kobiety, które przetrwały katastrofę")
surviving_females.head()
Kobiety, które przetrwały katastrofę
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 8 | 1 | 3 | female | 27.0 | 0 | 2 | 11.1333 | S | Third | woman | False | NaN | Southampton | yes | False |
| 9 | 1 | 2 | female | 14.0 | 1 | 0 | 30.0708 | C | Second | child | False | NaN | Cherbourg | yes | False |
# Grupowanie danych - średni wiek i cena biletu dla różnych klas
average_stats = titanic_data.groupby('class').agg({'age': 'mean', 'fare': 'mean'})
print("\nŚredni wiek i cena biletu dla różnych klas:\n", average_stats)
Średni wiek i cena biletu dla różnych klas:
age fare
class
First 38.233441 84.154687
Second 29.877630 20.662183
Third 25.140620 13.675550
W tym przykładzie przefiltrowano dane, aby uzyskać informacje tylko o kobietach, które przeżyły katastrofę, a także dokonano grupowania danych według klasy pasażerów, obliczając średni wiek oraz średnią cenę biletu w każdej klasie.
Przykład 3: Wizualizacja danych przy pomocy Pandasa#
# Histogram wieku pasażerów
titanic_data['age'].hist(bins=30)
# Wykres pudełkowy (boxplot) dla cen biletów w różnych klasach
titanic_data.boxplot(column='fare', by='class', grid=False)
<Axes: title={'center': 'fare'}, xlabel='class'>
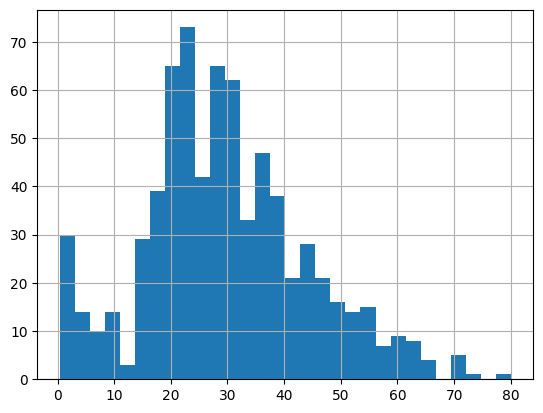
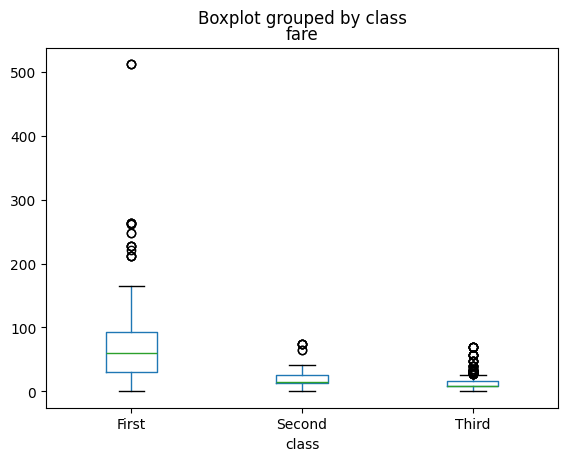
Pandas oferuje również proste metody wizualizacji danych. Powyżej wygenerowano histogram wieku pasażerów oraz wykres pudełkowy (boxplot) dla cen biletów w różnych klasach, co pozwala na szybkie zwizualizowanie rozkładu danych.
Pandas posiada uproszczone funkcje do wizualizacji danych, które delegują wykonanie określonych funkcji do pakietów jak np. matplotlib.
Polars#
Polars to nowoczesna, szybka i wielowątkowa alternatywa dla Pandas, napisana w języku Rust. Jest zoptymalizowana pod kątem wydajności, zwłaszcza przy pracy z dużymi zbiorami danych. Polars oferuje podobne struktury danych jak Pandas, w tym DataFrame, ale dzięki swojej architekturze może działać szybciej i efektywniej na dużych danych.
Zastosowania Polars
Polars jest używany do:
Szybkiej analizy dużych zbiorów danych.
Przetwarzania danych na wielu rdzeniach procesora (wielowątkowość).
Wykonywania operacji podobnych do Pandas, ale z lepszą wydajnością.
Dodatkowe materiały#
Przydatne linki - Polars
Przykład 1: Wczytaywanie i analiza dancyh#
import polars as pl
# Wczytywanie danych z pliku CSV
titanic_data = pl.read_csv(url)
# Przegląd pierwszych kilku wierszy
titanic_data.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| i64 | i64 | str | f64 | i64 | i64 | f64 | str | str | str | bool | str | str | str | bool |
| 0 | 3 | "male" | 22.0 | 1 | 0 | 7.25 | "S" | "Third" | "man" | true | null | "Southampton" | "no" | false |
| 1 | 1 | "female" | 38.0 | 1 | 0 | 71.2833 | "C" | "First" | "woman" | false | "C" | "Cherbourg" | "yes" | false |
| 1 | 3 | "female" | 26.0 | 0 | 0 | 7.925 | "S" | "Third" | "woman" | false | null | "Southampton" | "yes" | true |
| 1 | 1 | "female" | 35.0 | 1 | 0 | 53.1 | "S" | "First" | "woman" | false | "C" | "Southampton" | "yes" | false |
| 0 | 3 | "male" | 35.0 | 0 | 0 | 8.05 | "S" | "Third" | "man" | true | null | "Southampton" | "no" | true |
# Informacje o danych
print(titanic_data.describe())
shape: (9, 16)
┌────────────┬──────────┬──────────┬────────┬───┬──────┬─────────────┬───────┬──────────┐
│ statistic ┆ survived ┆ pclass ┆ sex ┆ … ┆ deck ┆ embark_town ┆ alive ┆ alone │
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ f64 ┆ str ┆ ┆ str ┆ str ┆ str ┆ f64 │
╞════════════╪══════════╪══════════╪════════╪═══╪══════╪═════════════╪═══════╪══════════╡
│ count ┆ 891.0 ┆ 891.0 ┆ 891 ┆ … ┆ 203 ┆ 889 ┆ 891 ┆ 891.0 │
│ null_count ┆ 0.0 ┆ 0.0 ┆ 0 ┆ … ┆ 688 ┆ 2 ┆ 0 ┆ 0.0 │
│ mean ┆ 0.383838 ┆ 2.308642 ┆ null ┆ … ┆ null ┆ null ┆ null ┆ 0.602694 │
│ std ┆ 0.486592 ┆ 0.836071 ┆ null ┆ … ┆ null ┆ null ┆ null ┆ null │
│ min ┆ 0.0 ┆ 1.0 ┆ female ┆ … ┆ A ┆ Cherbourg ┆ no ┆ 0.0 │
│ 25% ┆ 0.0 ┆ 2.0 ┆ null ┆ … ┆ null ┆ null ┆ null ┆ null │
│ 50% ┆ 0.0 ┆ 3.0 ┆ null ┆ … ┆ null ┆ null ┆ null ┆ null │
│ 75% ┆ 1.0 ┆ 3.0 ┆ null ┆ … ┆ null ┆ null ┆ null ┆ null │
│ max ┆ 1.0 ┆ 3.0 ┆ male ┆ … ┆ G ┆ Southampton ┆ yes ┆ 1.0 │
└────────────┴──────────┴──────────┴────────┴───┴──────┴─────────────┴───────┴──────────┘
W tym przykładzie załadowano dane o pasażerach Titanica za pomocą Polars i wyświetlono pierwsze kilka wierszy oraz podstawowe statystyki opisowe dla każdej kolumny. Operacje te będą bardzo szybkie w Polarsie, nawet przy dużych zbiorach danych.
Pozornie składnia Polarsa wydaje sie bardzo podobna do Pandasa, ale różni się w szczegółach, upodabniając go nieco do np. Sparka, używanego dla zastosowań Big Data.
Przykład 2: Filtrowanie i agregacja dnaych#
# Filtrowanie danych - tylko mężczyźni powyżej 30 lat
filtered_data = titanic_data.filter((pl.col('sex') == 'male') & (pl.col('age') > 30))
filtered_data
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| i64 | i64 | str | f64 | i64 | i64 | f64 | str | str | str | bool | str | str | str | bool |
| 0 | 3 | "male" | 35.0 | 0 | 0 | 8.05 | "S" | "Third" | "man" | true | null | "Southampton" | "no" | true |
| 0 | 1 | "male" | 54.0 | 0 | 0 | 51.8625 | "S" | "First" | "man" | true | "E" | "Southampton" | "no" | true |
| 0 | 3 | "male" | 39.0 | 1 | 5 | 31.275 | "S" | "Third" | "man" | true | null | "Southampton" | "no" | false |
| 0 | 2 | "male" | 35.0 | 0 | 0 | 26.0 | "S" | "Second" | "man" | true | null | "Southampton" | "no" | true |
| 1 | 2 | "male" | 34.0 | 0 | 0 | 13.0 | "S" | "Second" | "man" | true | "D" | "Southampton" | "yes" | true |
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 0 | 1 | "male" | 31.0 | 0 | 0 | 50.4958 | "S" | "First" | "man" | true | "A" | "Southampton" | "no" | true |
| 0 | 1 | "male" | 33.0 | 0 | 0 | 5.0 | "S" | "First" | "man" | true | "B" | "Southampton" | "no" | true |
| 0 | 3 | "male" | 47.0 | 0 | 0 | 9.0 | "S" | "Third" | "man" | true | null | "Southampton" | "no" | true |
| 0 | 3 | "male" | 33.0 | 0 | 0 | 7.8958 | "S" | "Third" | "man" | true | null | "Southampton" | "no" | true |
| 0 | 3 | "male" | 32.0 | 0 | 0 | 7.75 | "Q" | "Third" | "man" | true | null | "Queenstown" | "no" | true |
# Grupowanie danych - suma biletów dla różnych klas
fare_sum = titanic_data.group_by('class').agg(pl.sum('fare').alias('total_fare'))
print("\nSuma biletów dla różnych klas:\n", fare_sum)
Suma biletów dla różnych klas:
shape: (3, 2)
┌────────┬────────────┐
│ class ┆ total_fare │
│ --- ┆ --- │
│ str ┆ f64 │
╞════════╪════════════╡
│ Second ┆ 3801.8417 │
│ First ┆ 18177.4125 │
│ Third ┆ 6714.6951 │
└────────┴────────────┘
Podobnie jak w Pandas, Polars pozwala na filtrowanie i grupowanie danych. W powyższym kodzie przefiltrowano dane, aby wyświetlić tylko mężczyzn powyżej 30 roku życia, a następnie pogrupowano dane według klasy pasażerów, sumując ceny biletów.
Widzimy jednak, że zachodzą spore różnice w składni. Polars wykorzystuje funkcyjne podejście do wywoływania operacji, podobnie jak Apache Spark.
Biblioteki do operacji matematycznych i statystycznych#
NumPy#
NumPy jest fundamentalną biblioteką Pythona do obliczeń numerycznych. Oferuje wsparcie dla efektywnego przechowywania i manipulacji dużymi tablicami oraz macierzami wielowymiarowymi. Posiada również bogaty zbiór funkcji matematycznych umożliwiających wykonywanie operacji na tych danych, takich jak wszelkiego rodzaju arytmetyka, przekształcenia algebraiczne, badanie funkcji, i inne.
Znajomość NumPy, zwłaszcza w zakresie macierzy jest fundamentalną umiejętnością dla działań w zakresie uczenia maszynowego.
Zastosowania NumPy
NumPy jest często używany do:
Tworzenia i manipulowania macierzami: dodawanie, mnożenie, transpozycja, itd.
Wszelkich innych działań z zakresu algebry liniowej, jak np. rozwiazywanie układów równań.
Dodatkowe materiały#
Przykład 1: Tworzenie macierzy i podstawowe operacje na nich#
import numpy as np
# Tworzenie macierzy 3x3
A = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# Transpozycja macierzy
A_transposed = A.T
# Mnożenie macierzy
B = np.array([[9, 8, 7],
[6, 5, 4],
[3, 2, 1]])
result = np.dot(A, B)
print("Macierz A:\n", A)
print("Macierz A po transpozycji:\n", A_transposed)
print("Wynik mnożenia A i B:\n", result)
Macierz A:
[[1 2 3]
[4 5 6]
[7 8 9]]
Macierz A po transpozycji:
[[1 4 7]
[2 5 8]
[3 6 9]]
Wynik mnożenia A i B:
[[ 30 24 18]
[ 84 69 54]
[138 114 90]]
W powyższym kodzie utworzono macierz A o wymiarach 3x3, a następnie dokonano jej transpozycji. Następnie wykonano operację mnożenia macierzy A z macierzą B za pomocą funkcji np.dot.
Przykład 2: Rozwiązywanie układów równań liniowych#
W poniższym przykładzie wykorzystamy numpy do rozwiazania układu równań liniowych:
X = np.array([
[1., 2.],
[3, -5]
])
y = np.array([4, 1])
coef = np.linalg.solve(X, y)
print(f"Rozwiązanie układu to: [x,y] = {coef}")
Rozwiązanie układu to: [x,y] = [2. 1.]
SciPy#
SciPy to rozbudowana biblioteka dla zaawansowanych obliczeń naukowych. Oferuje funkcje do optymalizacji procesów, rozwiązywania równań różniczkowych, statystyki, przetwarzania sygnałów i wielu innych zadań. W tej sekcji skupimy się na module scipy.stats, który zawiera zestaw narzędzi statystycznych, w tym rozkłady prawdopodobieństwa, testy statystyczne, oraz funkcje estymacji.
Zastosowania SciPy
SciPy jest używany do:
Przeprowadzania testów statystycznych (np. testu t-Studenta, testu chi-kwadrat, etc).
Estymacji parametrów rozkładów.
Analizy regresji i korelacji.
Dodatkowe materiały#
Przydatne linki - SciPy
Przykład 1: test T-studenta dla dwóch próbek#
from scipy import stats
# Przykładowe dane: dwie próbki
sample1 = [5, 7, 8, 9, 10]
sample2 = [6, 9, 7, 12, 11]
# Test t-Studenta
t_stat, p_value = stats.ttest_ind(sample1, sample2)
print("t-statystyka:", t_stat)
print("p-wartość:", p_value)
t-statystyka: -0.8401680504168061
p-wartość: 0.4252097205513896
W powyższym kodzie przeprowadzono test t-Studenta dla dwóch niezależnych próbek danych. Wynikiem jest t-statystyka oraz p-wartość, która mówi nam o tym, czy możemy odrzucić hipotezę zerową o równości średnich w populacji.
Przykad 2: Estymacja parametrów rozkładu#
# Przykładowe dane - normalnei nie wiemy, z jakiego rozkładu by pochodziły :)
data = np.random.normal(loc=10, scale=3, size=1000)
# Estymacja parametrów "nieznanego" rozkładu na podstawie danych
mu, std = stats.norm.fit(data)
print("Estymowana średnia (mu):", mu)
print("Estymowana odchylenie standardowe (std):", std)
Estymowana średnia (mu): 10.264603450844067
Estymowana odchylenie standardowe (std): 2.9264260614737014
W tym przykładzie przeprowadzono estymację parametrów rozkładu normalnego (średniej oraz odchylenia standardowego) na podstawie wygenerowanej próbki danych.
Biblioteki do wizualizacji danych#
Wizualizacja danych to kluczowy element pracy z danymi, umożliwiający efektywne komunikowanie wyników analizy, odkrywanie wzorców i trendów, a także weryfikację hipotez. W tej sekcji omówimy trzy popularne biblioteki do wizualizacji danych: matplotlib, seaborn oraz plotly.
Matplotlib#
Matplotlib to podstawowa biblioteka do tworzenia wykresów w Pythonie. Jest niezwykle elastyczna i umożliwia tworzenie szerokiej gamy obrazów od prostych wykresów liniowych po skomplikowane wizualizacje 3D. Matplotlib jest często używany jako fundament dla innych bibliotek takich jak Seaborn. Oferuje kolosalną ilość funkcjonalności, których poznanie wymaga sporo czasu i wysiłku. W praktyce, zwykle uczymy się tych elementów, które najbardziej nam się przydadzą w prowadzonych analizach.
Zastosowania Matplolib
Matplotlib jest używany do:
Tworzenia wykresów liniowych, słupkowych, kołowych, histogramów, i wielu innych.
Dostosowywania elementów wykresu, takich jak osie, legendy, etykiety, kolory.
Tworzenia interaktywnych wykresów i animacji.
Dodatkowe materiały#
Przydatne linki - Matplotlib
Przykład 1: Prosty wykres liniowy#
import matplotlib.pyplot as plt
# Przykładowe dane
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
# Tworzenie wykresu liniowego
plt.plot(x, y, marker='o')
# Dodawanie tytułu i etykiet osi
plt.title('Prosty wykres liniowy')
plt.xlabel('X')
plt.ylabel('Y')
# Wyświetlanie wykresu
plt.show()
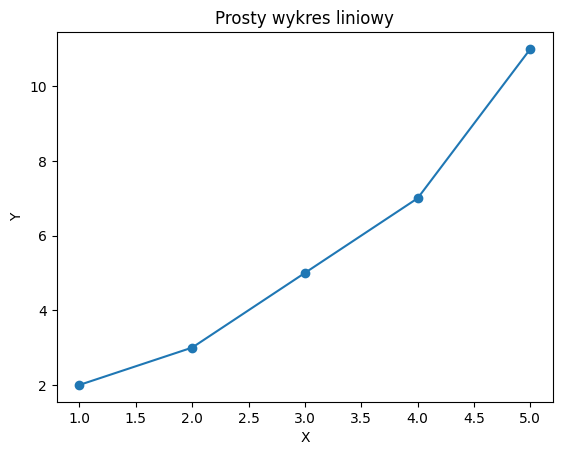
W powyższym przykładzie utworzono prosty wykres liniowy z pięcioma punktami. Dodano również tytuł wykresu oraz etykiety osi X i Y. Wykres został wygenerowany za pomocą funkcji plt.plot i wyświetlony z użyciem plt.show.
Przykład 2: Tworzenie histogramu i wykresu pudełkowego#
# Generowanie losowych danych
data = np.random.normal(0, 1, 1000)
# Tworzenie histogramu
plt.hist(data, bins=30, alpha=0.7, color='blue')
plt.title('Histogram rozkładu normalnego')
plt.xlabel('Wartość')
plt.ylabel('Częstość')
plt.show()
# Tworzenie wykresu pudełkowego
plt.boxplot(data)
plt.title('Wykres pudełkowy')
plt.show()
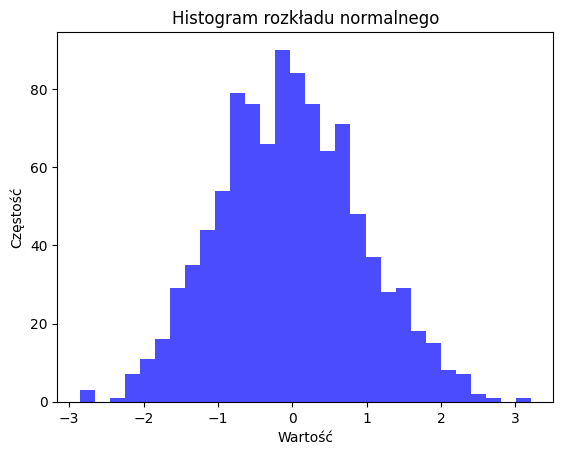
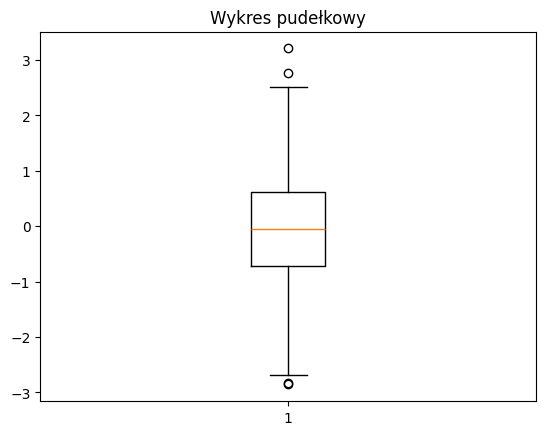
W powyższym kodzie najpierw wygenerowano losowy zbiór danych o rozkładzie normalnym. Następnie utworzono histogram dla tych danych, a także wykres pudełkowy, który pomaga wizualizować rozkład oraz identyfikować wartości odstające.
Seaborn#
Seaborn to biblioteka zbudowana na bazie Matplotlib, która upraszcza proces tworzenia atrakcyjnych wizualnie wykresów. Seaborn oferuje domyślne style i palety kolorów, które poprawiają estetykę wykresów, a także dodatkowe funkcje ułatwiające wizualizację złożonych relacji między zmiennymi, jak wykresy rozrzutu z liniami regresji, wykresy skrzynkowe, czy wykresy gęstości.
Zastosowania Seaborn
Seaborn jest używany do:
Tworzenia bardziej zaawansowanych wykresów, jak wykresy korelacji, heatmapy.
Wizualizacji rozkładów danych, takich jak wykresy gęstości, violin ploty.
Łatwego łączenia danych kategorycznych z ilościowymi na wykresach.
Dodatkowe materiały#
Przydatne linki - Seaborn
Przykład 1: Tworzenie wykresu rozrzutu z linią regresji#
import seaborn as sns
# Wczytywanie danych z seaborn
tips = sns.load_dataset('tips')
# Tworzenie wykresu rozrzutu z linią regresji
sns.lmplot(x='total_bill', y='tip', data=tips)
# Dodawanie tytułu wykresu
plt.title('Relacja między rachunkiem a napiwkiem')
plt.show()
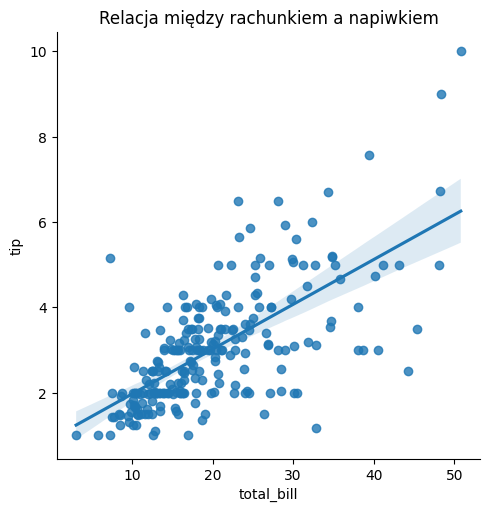
W powyższym przykładzie użyto wbudowanego w Seaborn zbioru danych tips i utworzono wykres rozrzutu, przedstawiający relację między wysokością rachunku a napiwkiem, z nałożoną linią regresji. Wykres jest automatycznie dostosowany do estetyki Seaborn.
Przykład 2: tworzenie wykresu pudełkowego (boxplot) i heatmapy#
# Wykres skrzynkowy dla napiwków w zależności od dnia tygodnia
sns.boxplot(x='day', y='tip', data=tips)
plt.title('Napiwki w zależności od dnia tygodnia')
plt.show()
# Tworzenie macierzy korelacji
corr = tips[['total_bill', 'tip', 'size']].corr()
# Heatmapa korelacji
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('Macierz korelacji')
plt.show()
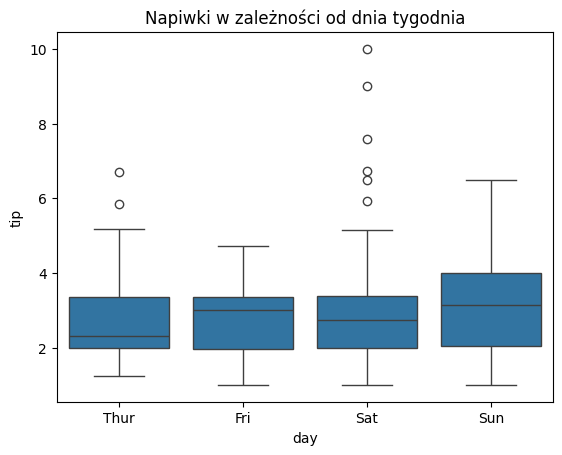
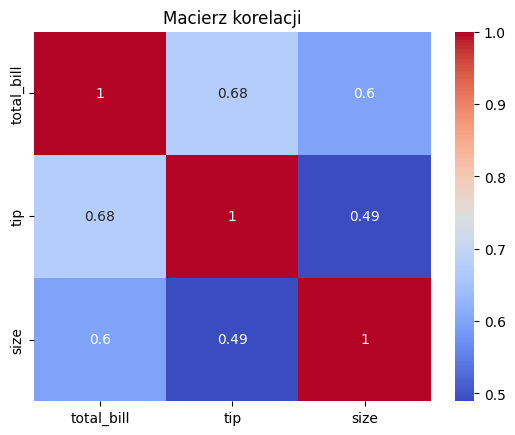
Najpierw stworzono wykres skrzynkowy, który porównuje rozkład napiwków w zależności od dnia tygodnia. Następnie, na podstawie macierzy korelacji obliczonej dla danych z tips, wygenerowano heatmapę z zaznaczonymi wartościami korelacji pomiędzy różnymi zmiennymi.
Przykład 3: Tworzenie zaawansowanych wykresów wielofacetowych#
import seaborn as sns
# Load the Titanic dataset
titanic_data = sns.load_dataset('titanic')
# Create a FacetGrid with multiple facets
g = sns.FacetGrid(titanic_data, col='class', row='sex', hue='survived', height=4, sharey=False)
# Add a scatter plot to each facet
g.map(sns.scatterplot, 'age', 'fare')
# Add a regression line to each facet
g.map(sns.regplot, 'age', 'fare')
# Set titles for each facet
g.set_titles('Class: {col_name}, Sex: {row_name}')
# Add a legend
g.add_legend()
# Show the plot
plt.show()
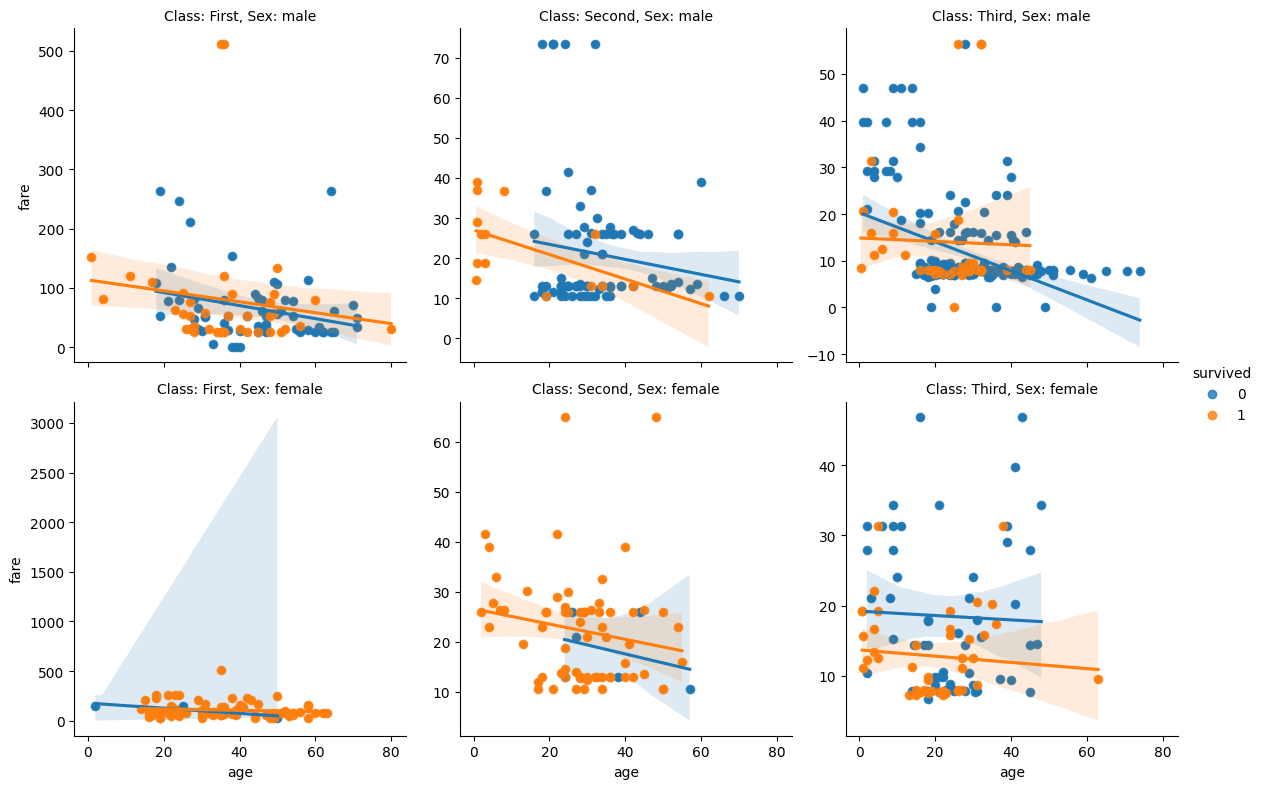
W przykładzie powyżej wykonano tzw. wykres wielofasetowy z użyciem Seaborn, dzieląc zbiór danych na różne kategorie i przedstawiając na kilku planszach. Jednocześnie nałożono także linie regresji.
Plotly#
Plotly to biblioteka do tworzenia interaktywnych wykresów, która jest idealna do publikowania wyników analizy danych online. W przeciwieństwie do Matplotlib czy Seaborn, Plotly pozwala na tworzenie interaktywnych wizualizacji, które można łatwo integrować z aplikacjami internetowymi. Plotly obsługuje szeroki zakres wykresów, od podstawowych po zaawansowane, takie jak wykresy 3D, mapy geograficzne, wykresy sankey’ego i wiele innych.
Co ważne, Plotly można operować na kilku poziomach złożoności:
Plotly Express- wysokopoziomowy interfejs do tworzenia wykresów, który pozwala na szybkie generowanie wykresów z minimalną ilością kodu.Plotly Graph Objects- niskopoziomowy interfejs, który umożliwia pełną kontrolę nad wyglądem i zachowaniem wykresu.
Zastosowania Plotly
Plotly jest używany do:
Tworzenia interaktywnych wykresów, które można łatwo publikować online.
Tworzenia zaawansowanych wykresów, takich jak wykresy 3D, mapy geograficzne, wykresy sankey’ego.
Integracji z aplikacjami internetowymi.
Dodatkowe materiały#
Przydatne linki - Plotly
Renderowanie wykresów w notebookach i książce
Wykresy tworzone w Plotly są pod spodem konwertowane do HTML. Z tego względu nie zawsze prawidłowo renderują się w postaci Jupyter Notebooka oraz w materiałach takich, jak ta książka. Warto zatem uruchomić kod w swoim środowisku, aby zobaczyć wykresy w pełnej krasie - np. w Google Colab albo lokalnie.
Przykład 1: Tworzenie interaktywnego wykresu liniowego#
import plotly.express as px
# Przykładowe dane
df = px.data.gapminder().query("country=='Canada'")
# Tworzenie interaktywnego wykresu liniowego
fig = px.line(df, x='year', y='gdpPercap', title='GDP per Capita in Canada')
# Wyświetlanie wykresu
fig.show()
W tym przykładzie użyto wbudowanego zbioru danych gapminder i utworzono interaktywny wykres liniowy przedstawiający wzrost PKB na mieszkańca w Kanadzie na przestrzeni lat. Wykres można eksplorować, np. przybliżając wybrane fragmenty lub klikając na punkty danych.
Przykład 2: Tworzenie wykresu 3D#
# Przykładowe dane
df = px.data.iris()
# Tworzenie wykresu 3D
fig = px.scatter_3d(df, x='sepal_length', y='sepal_width', z='petal_length',
color='species', title='3D Scatter Plot - Iris Dataset')
# Wyświetlanie wykresu
fig.show()
W tym przykładzie stworzono trójwymiarowy wykres rozrzutu dla zbioru danych iris, który jest często używany do testowania algorytmów uczenia maszynowego. Kolory na wykresie reprezentują różne gatunki irysów, a wykres jest interaktywny, co umożliwia obracanie i przybliżanie przestrzeni 3D.
Biblioteki uczenia maszynowego#
W poniższej sekcji omówimy wyłącznie najważniejsze biblioteki przeznaczone do uczenia maszynowego. Warto zaznaczyć, że w tej dziedzinie istnieje wiele innych narzędzi, które są używane w zależności od konkretnego problemu, takich jak np. XGBoost, LightGBM, CatBoost do modeli gradient boosting, czy TensorFlow, PyTorch, Keras do sieci neuronowych. Nie sposób tutaj wymienić i przedstawić ich wszystkich.
Co więcej - nawet w obrębie omówionych tutaj bibliotek jak scikit-learn znajduja się setki (jeśli nie tysiące) różnych algorytmów, które można wykorzystać do rozwiązania konkretnego problemu. Warto zatem zapoznać się z oficjalną dokumentacją, aby dowiedzieć się, jakie funkcjonalności są dostępne.
W tym opracowaniu chcemy przedstawić tylko przykłady zastosowania, oraz podstawowe funkcjonalności, które są dostępne w wybranych bibliotekach, wskazując punkt startowy do dalszej eksploracji narzędzi.
Scikit-learn#
Scikit-learn to jedna z najbardziej wszechstronnych i najczęściej używanych bibliotek do uczenia maszynowego w Pythonie. Oferuje narzędzia do przetwarzania danych, uczenia nadzorowanego i nienadzorowanego, a także do oceny i wyboru modeli. Scikit-learn jest idealny do szybkiego prototypowania modeli oraz do realizacji klasycznych zadań ML, takich jak klasyfikacja, regresja, klasteryzacja czy redukcja wymiarów.
Ważne jest, że Scikit-learn udosstępnia spójne API, czyli interfejs programistyczny, który jest taki sam dla wszystkich algorytmów. Dzięki temu, nauka i stosowanie różnych modeli jest znacznie ułatwione!
Zastosowania Scikit-learn
Scikit-learn jest używany do:
Wszelkich zadań z zakresu klasycznego uczenia maszynowego, (ang. classic ML), czyli klasyfikacji, regresji, klasteryzacji, redukcji wymiarów.
Walidacji krzyżowej i projektowania eksperymentów.
Wyliczania metryk i sprawdzania jakości modeli.
Dodatkowe materiały#
Przydatne linki - Scikit-learn
Oficjalny przewodnik i podręcznik Scikit-learn - to jest nieocenione źródło wiedzy, podzielone na rozdziały i sekcje. Można je traktować jak pełnoprawny podręcznik do uczenia maszynowego.
Przykład 1: Klasyfikacja za pomocą SVM i przegląd typowego API#
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# Wczytywanie wbudowanego zbioru danych (Iris)
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Podział na zbiór treningowy i testowy
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Tworzenie modelu SVM i trenowanie
model = SVC(kernel='linear')
model.fit(X_train, y_train)
# Przewidywanie na zbiorze testowym
y_pred = model.predict(X_test)
# Ocena modelu
accuracy = accuracy_score(y_test, y_pred)
print(f"Dokładność modelu SVM: {accuracy:.2f}")
Dokładność modelu SVM: 1.00
W powyższym przykładzie użyto Scikit-learn do klasyfikacji gatunków irysów za pomocą maszyny wektorów nośnych (SVM) z liniowym kernelem. Model został przetrenowany na zbiorze treningowym, a następnie oceniony na zbiorze testowym, osiągając określoną dokładność.
Charakterystyczna jest obecność następujących elementów API:
fit- trenowanie modelu na danych treningowych.predict- predykcja na danych testowych.Zastosowanie metryki, w tym przypadku
accuracy_score, poprzez jej wywołanie z sygnaturą:METRYKA(y_true, y_pred).
Taki sposób działania będzie wspólny dla niemal wszystkich modeli w Scikit-learn.
Przykład 2: Klasteryzacja z pomocą algorytmu K-średnich#
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Wygenerowanie losowych danych 2D
X, _ = datasets.make_blobs(n_samples=300, centers=4, random_state=42)
# Klasteryzacja przy użyciu k-means
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
# Wizualizacja wyników
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red', marker='X')
plt.title('Klasteryzacja k-means')
plt.show()
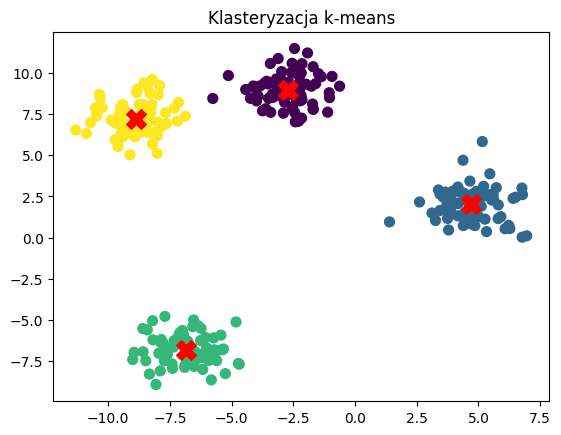
Powyższy kod pokazuje, jak użyć k-means do klasteryzacji danych 2D. Po wygenerowaniu losowych danych, zastosowano algorytm k-means, który podzielił dane na cztery klastry. Wynik został zwizualizowany na wykresie z zaznaczonymi centroidami klastrów.
PyTorch + Pytorch Lightning#
PyTorch to jedna z najpopularniejszych bibliotek do uczenia głębokiego (ang. deep learning) oraz innych zadań związanych z ML. PyTorch został opracowany przez MEta AI Research i jest znany ze swojej elastyczności i łatwości użycia, szczególnie w badaniach naukowych. Umożliwia definiowanie, trenowanie i testowanie sieci neuronowych, wspiera również dynamiczne przetwarzanie grafów obliczeniowych, co jest jego dużą zaletą w porównaniu do innych frameworków.
PyTorch Lightning to wysokopoziomowy framework zbudowany na bazie PyTorch, który ma na celu uproszczenie procesu trenowania sieci neuronowych. PyTorch jest bardzo elastyczny, ale ta elastyczność może prowadzić do skomplikowanego kodu, szczególnie gdy projekt staje się bardziej złożony. PyTorch Lightning pomaga w rozdzieleniu kodu związanego z logiką modelu od kodu związanego z infrastrukturą, taką jak trenowanie, walidacja, logowanie i zarządzanie eksperymentami. Dzięki temu kod staje się bardziej czytelny, łatwiejszy do debugowania i skalowania.
Zastosowania PyTorch
PyTorch jest używany do:
Tworzenia i trenowania sieci neuronowych.
Badań naukowych i tworzenia innowacyjnych modeli sieci neuronowych.
W czym pomaga PyTorch Lightning:
Struktura kodu: Uporządkowanie kodu poprzez oddzielenie logiki modelu od logiki trenowania.
Skalowanie: Umożliwia łatwe przejście od trenowania na pojedynczym GPU do trenowania na klastrach wielo-GPU czy TPU bez konieczności zmiany kodu.
Zarządzanie eksperymentami: Automatyczne logowanie, punkty zapisu (ang. checkpointing), oraz wsparcie dla integracji z narzędziami do monitorowania eksperymentów (np. TensorBoard).
Uproszczona walidacja i testowanie: PyTorch Lightning ułatwia implementację pętli walidacyjnych i testowych, co jest szczególnie przydatne w większych projektach.
Dodatkowe materiały#
Przydatne linki - PyTorch
Deep Learning Fundamendtals - kurs - fantastyczny (i darmowy) kurs poświęcony bibliotece Pytorch oraz Pytorch Lightning, prowadzony przez dr Sebastiana Raschkę, autora wielu narzędzi i publikacji z zakresu ML. Fantastyczne źródło wiedzy.
Przykład 1: Prosta sieć neuronowa do klasyfikacji danych tabelaryczncyh#
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch.utils.data import DataLoader, TensorDataset
from typing import Tuple
# Wczytywanie i przygotowanie danych
data = load_wine()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=42)
# Normalizacja danych
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Konwersja do tensora
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.long)
# Tworzenie DataLoaderów
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# Definiowanie modelu MLP
class MLP(nn.Module):
def __init__(self, dims: Tuple[int, ...]):
super().__init__()
layers = []
for dim_in, dim_out in zip(dims, dims[1:]):
layer = nn.Linear(dim_in, dim_out)
layers.append(layer)
layers.append(nn.ReLU())
self.net = nn.Sequential(*layers[:-1])
def forward(self, x):
out = self.net(x)
return out
# Inicjalizacja modelu, funkcji kosztu i optymalizatora
torch.manual_seed(42)
model = MLP([X_train.shape[1], 32, 16, len(data.target_names)])
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Trenowanie modelu
for epoch in range(20):
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(train_loader):.4f}")
# Ocena modelu
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Dokładność na zbiorze testowym: {100 * correct / total:.2f}%")
Epoch 1, Loss: 1.0892
Epoch 2, Loss: 1.0654
Epoch 3, Loss: 1.0424
Epoch 4, Loss: 1.0159
Epoch 5, Loss: 0.9890
Epoch 6, Loss: 0.9614
Epoch 7, Loss: 0.9311
Epoch 8, Loss: 0.8964
Epoch 9, Loss: 0.8612
Epoch 10, Loss: 0.8256
Epoch 11, Loss: 0.7891
Epoch 12, Loss: 0.7513
Epoch 13, Loss: 0.7106
Epoch 14, Loss: 0.6666
Epoch 15, Loss: 0.6277
Epoch 16, Loss: 0.5841
Epoch 17, Loss: 0.5435
Epoch 18, Loss: 0.5027
Epoch 19, Loss: 0.4608
Epoch 20, Loss: 0.4207
Dokładność na zbiorze testowym: 92.59%
W powyższym przykładzie zdefiniowano model MLP, który składa się z dwóch ukrytych warstw (z 32 i 16 neuronami). Dane wejściowe zostały przeskalowane przy użyciu standardowej normalizacji. Model został przetrenowany przez 20 epok, a następnie oceniony na zbiorze testowym.
Przykład 2: MLP do regresji na danych tabelarycznych#
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch.utils.data import DataLoader, TensorDataset
from typing import Tuple
# Wczytywanie i przygotowanie danych
data = fetch_california_housing()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=42)
# Normalizacja danych
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Konwersja do tensora
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)
# Tworzenie DataLoaderów
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# Definiowanie modelu MLP do regresji
class MLPRegressor(nn.Module):
def __init__(self, dims: Tuple[int, ...]):
super().__init__()
layers = []
for dim_in, dim_out in zip(dims, dims[1:]):
layer = nn.Linear(dim_in, dim_out)
layers.append(layer)
layers.append(nn.ReLU())
self.net = nn.Sequential(*layers[:-1])
def forward(self, x):
out = self.net(x)
return out
# Inicjalizacja modelu, funkcji kosztu i optymalizatora
torch.manual_seed(42)
model = MLPRegressor([X_train.shape[1], 32, 16, 1])
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Trenowanie modelu
for epoch in range(25):
running_loss = 0.0
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(train_loader):.4f}")
# Ocena modelu
model.eval()
with torch.no_grad():
test_predictions = model(X_test)
mse = criterion(test_predictions, y_test)
print(f"MSE na zbiorze testowym: {mse.item():.4f}")
Epoch 1, Loss: 1.4307
Epoch 2, Loss: 0.4944
Epoch 3, Loss: 0.4216
Epoch 4, Loss: 0.3952
Epoch 5, Loss: 0.3777
Epoch 6, Loss: 0.3673
Epoch 7, Loss: 0.3571
Epoch 8, Loss: 0.3505
Epoch 9, Loss: 0.3416
Epoch 10, Loss: 0.3340
Epoch 11, Loss: 0.3266
Epoch 12, Loss: 0.3242
Epoch 13, Loss: 0.3173
Epoch 14, Loss: 0.3122
Epoch 15, Loss: 0.3087
Epoch 16, Loss: 0.3120
Epoch 17, Loss: 0.3042
Epoch 18, Loss: 0.3021
Epoch 19, Loss: 0.2984
Epoch 20, Loss: 0.2955
Epoch 21, Loss: 0.2982
Epoch 22, Loss: 0.2937
Epoch 23, Loss: 0.2940
Epoch 24, Loss: 0.2911
Epoch 25, Loss: 0.2893
MSE na zbiorze testowym: 0.2996
W tym przykładzie zdefiniowano model MLP do zadania regresji. Model składa się z dwóch ukrytych warstw (32 i 16 neuronów) i jednej warstwy wyjściowej z jednym neuronem (do regresji). Model został przetrenowany przez 25 epok, a następnie oceniony na zbiorze testowym za pomocą miary błędu średniokwadratowego (MSE).
Przykład 3: Implementacja prostej sieci neuronowej w Pytorch Lightning#
import torch
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset, random_split
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from typing import Tuple
import pytorch_lightning as pl
# Wczytywanie i przygotowanie danych
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=42)
# Normalizacja danych
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Konwersja do tensora
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.long)
# Tworzenie DataLoaderów
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=16, shuffle=False)
# Definiowanie modelu MLP za pomocą PyTorch Lightning
class IrisMLP(pl.LightningModule):
def __init__(self, dims: Tuple[int, ...]):
super().__init__()
layers = []
for dim_in, dim_out in zip(dims, dims[1:]):
layer = torch.nn.Linear(dim_in, dim_out)
layers.append(layer)
layers.append(torch.nn.ReLU())
self.network = torch.nn.Sequential(*layers[:-1])
def forward(self, x):
out = self.network(x)
return out
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = F.cross_entropy(y_hat, y)
self.log('train_loss', loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
val_loss = F.cross_entropy(y_hat, y)
self.log('val_loss', val_loss)
return val_loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
# Trenowanie modelu za pomocą PyTorch Lightning
model = IrisMLP([X_train.shape[1], 32, 16, len(data.target_names)])
trainer = pl.Trainer(max_epochs=20)
trainer.fit(model, train_loader, test_loader)
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
/home/runner/.cache/pypoetry/virtualenvs/dsbook-K6kLFozp-py3.11/lib/python3.11/site-packages/pytorch_lightning/trainer/connectors/logger_connector/logger_connector.py:75: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `pytorch_lightning` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
| Name | Type | Params | Mode
-----------------------------------------------
0 | network | Sequential | 739 | train
-----------------------------------------------
739 Trainable params
0 Non-trainable params
739 Total params
0.003 Total estimated model params size (MB)
6 Modules in train mode
0 Modules in eval mode
/home/runner/.cache/pypoetry/virtualenvs/dsbook-K6kLFozp-py3.11/lib/python3.11/site-packages/pytorch_lightning/trainer/connectors/data_connector.py:424: The 'val_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=3` in the `DataLoader` to improve performance.
/home/runner/.cache/pypoetry/virtualenvs/dsbook-K6kLFozp-py3.11/lib/python3.11/site-packages/pytorch_lightning/trainer/connectors/data_connector.py:424: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=3` in the `DataLoader` to improve performance.
/home/runner/.cache/pypoetry/virtualenvs/dsbook-K6kLFozp-py3.11/lib/python3.11/site-packages/pytorch_lightning/loops/fit_loop.py:298: The number of training batches (7) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
`Trainer.fit` stopped: `max_epochs=20` reached.
W powyższym przykładzie:
Model: Zdefiniowano model MLP będący modułem Pytorch Lighting obsługującym predefiniowane funkcje takie, jak
forward,training_step,validation_step,configure_optimizers.Dane: Dane z zestawu Iris zostały przeskalowane, a następnie skonwertowane na tensory PyTorch.
Trening: Model został przetrenowany przez 20 epok. PyTorch Lightning automatycznie zarządza procesem trenowania, w tym logowaniem strat/kosztów (train_loss, val_loss) i optymalizacją modelu.
MLXtend#
Mlxtend (Machine Learning Extensions) to biblioteka, która rozszerza możliwości Scikit-learn, oferując dodatkowe narzędzia, takie jak metody wyboru cech, łączenie klasyfikatorów, różnorodne algorytmy do klasyfikacji i regresji, a także funkcje do wizualizacji wyników. Mlxtend jest idealny dla osób, które chcą szybko przetestować różne techniki ML, które nie są wbudowane w Scikit-learn.
MLXtend pomaga też przy analizowaniu możliwości poszczególnych klas model, oraz ich własności. W tym podręczniku w rozdziale poświęconym obciążeniom indukcyjnym modeli ML, użyliśmy właśnie MLXtend.
Zastosowania MLXtend
Mlxtend jest używany do:
Wyboru cech i redukcji wymiarów.
Łączenia klasyfikatorów i regresorów.
Wizualizacji wyników i analizy modeli.
Dodatkowe materiały#
Przydatne linki - MLXtend
Oficjalna dokumentacja MLXtend - dokumentacja jest też dodatkowo bardzo dobrym podręcznikiem.
Przykład 1: Łączenie modeli klasyfikacji#
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from mlxtend.classifier import EnsembleVoteClassifier
from mlxtend.plotting import plot_decision_regions
import matplotlib.pyplot as plt
# Wczytywanie danych
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X[:, :2], y, test_size=0.3, random_state=42)
# Definiowanie modeli bazowych
clf1 = RandomForestClassifier(random_state=1)
clf2 = GradientBoostingClassifier(random_state=1)
# Łączenie modeli
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2], voting='soft')
# Trenowanie i wizualizacja wyników
eclf.fit(X_train, y_train)
plot_decision_regions(X_train, y_train, clf=eclf),
plt.title('Łączenie modeli za pomocą Mlxtend')
plt.show()
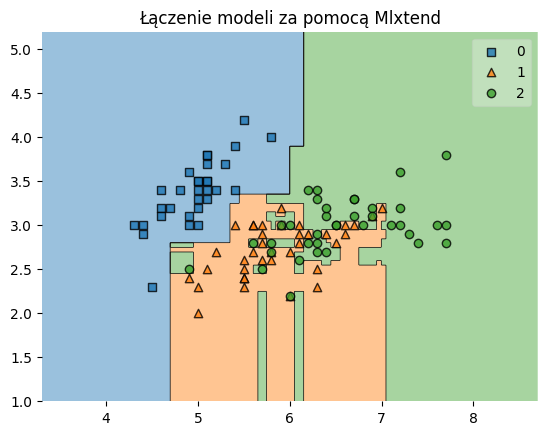
W powyższym przykładzie wykorzystano Mlxtend do połączenia dwóch : lasu losowego i gradient boosting. Modele zostały połączone w celu stworzenia bardziej stabilnego i dokładnego modelu końcowego, a wynik został zwizualizowany za pomocą funkcji plot_decision_regions, ukazującą regiony działania/podejmowania decyzji przez modele.
Przykład 2: Wizualizacja macierzy pomyłek#
from mlxtend.plotting import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
# Przewidywanie na zbiorze testowym
y_pred = eclf.predict(X_test)
# Tworzenie macierzy pomyłek
cm = confusion_matrix(y_test, y_pred)
# Wizualizacja macierzy pomyłek
fig, ax = plot_confusion_matrix(conf_mat=cm, figsize=(6, 6))
plt.title('Macierz pomyłek')
plt.show()
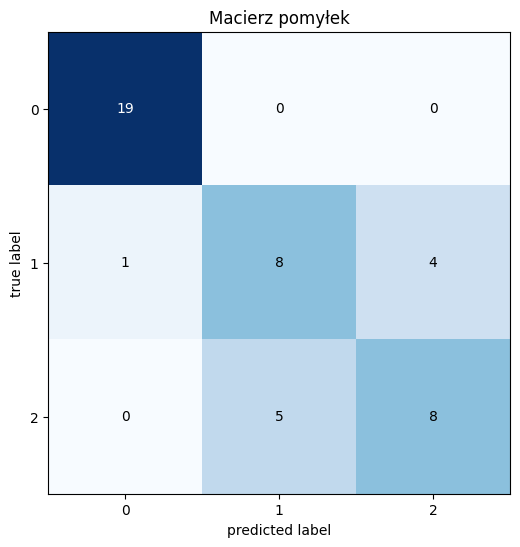
Kod ten pokazuje, jak za pomocą Mlxtend można łatwo wizualizować macierz pomyłek. Macierz ta przedstawia liczbę poprawnych i błędnych klasyfikacji dokonanych przez model, co jest kluczowym narzędziem do oceny jego wydajności.
Optuna#
Optuna to biblioteka do automatycznej optymalizacji hiperparametrów, która pomaga w znalezieniu najlepszych ustawień parametrów modeli ML poprzez próbkowanie ich z różnych rozkładów. Optuna jest bardzo elastyczna i oferuje zaawansowane techniki optymalizacji, takie jak próbkowanie TPE (ang. Tree-structured Parzen Estimator) i optymalizacja oparta na modelu bayesowskim. Jest to szczególnie przydatne w automatyzacji procesu strojenia modeli, co jest jednym z bardziej czasochłonnych aspektów pracy nad ML.
Zastosowania Optuny
Optuna jest używana do:
Automatycznego strojenia hiperparametrów modeli ML.
Optymalizacji modeli ML w celu uzyskania najlepszych wyników.
Dodatkowe materiały#
Przydatne linki - Optuna
Przykład: Optymalizacja parmetrów klasyfikatora#
import optuna
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
optuna.logging.set_verbosity(optuna.logging.WARNING)
# Wczytywanie danych
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Funkcja celu
def objective(trial):
C = trial.suggest_float('C', 1e-4, 1e2, log=True)
gamma = trial.suggest_float('gamma', 1e-4, 1e1, log=True)
model = SVC(C=C, gamma=gamma)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
return accuracy_score(y_test, y_pred)
# Tworzenie study i optymalizacja
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)
print("Najlepsze parametry:", study.best_params)
print("Najlepsza dokładność:", study.best_value)
Najlepsze parametry: {'C': 24.956723007179015, 'gamma': 0.012497469517543196}
Najlepsza dokładność: 1.0
Biblioteki do pracy z szeregami czasowymi#
Analiza szeregów czasowych jest jedna z kluczowych dziedzin w Data Science, szczególnie w kontekście prognozowania danych finansowych, czy ekonomicznych. Python oferuje różnorodne narzędzia do pracy z szeregami czasowymi. W tej sekcji omówimy dwie biblioteki: statsmodels oraz statsforecast z Nixtlaverse.
Zwłaszcza ta ostatnia rodzina/grupa bibliotek zgrupowana pod wspólną nazwą jest bardzo interesująca - oferuje m. in. moduły prognozowania opartego o uczenie maszynowe (mlforecast), oraz sieci neuronowe (neuralforecast) w tym samym ekosystemie.
Statsmodels#
Statsmodels to wszechstronna biblioteka Pythona, która oferuje zaawansowane narzędzia do modelowania statystycznego. Biblioteka ta jest szczególnie użyteczna w analizie szeregów czasowych, oferując modele takie jak ARIMA, SARIMAX, modele stacjonarne oraz narzędzia do diagnostyki i oceny modeli.
Statsmodels - kłopoty z czytelnością
Wiele osób zauważa, że dokumentacja tego narzędzia pozostawia wiele do życzenia, podobnie jak czytelność i przejrzystość kodu. Jest to co prawda kwestia gustu, ale rzeczywiście, z punktu widzenia inżynierii oprogramowania, dobrych praktyk i przejrzystości kodu - statsmodels ma wiele do poprawy.
Ciężko jest znaleźć interesujące nas tematy w dokumentacji, a także zrozumieć, jakie są dostępne funkcjonalności. Warto zatem korzystać z dodatkowych materiałów, takich jak kursy online, czy przewodniki, które pomogą w zrozumieniu tej biblioteki. Niestety - nierzadko dokumentacja nijak się ma do tego, co aktualnie jest zaimplementowane w określonej wersji :/
Zastosowania Statsmodels
Statsmodels jest używany do:
Modelowania szeregów czasowych, w tym ARIMA, SARIMAX.
Diagnostyki modeli szeregów czasowych.
Analizy statystycznej i modelowania danych.
Dodatkowe materiały#
Przydatne linki - Statsmodels
Przykład 1: Modelowanie ARIMA dla danych szeregów czasowych#
import pandas as pd
import numpy as np
import statsmodels.api as sm
from matplotlib import pyplot as plt
# Przykładowe dane: symulacja szeregu czasowego
np.random.seed(42)
data = np.cumsum(np.random.randn(100)) + 50
dates = pd.date_range('2023-01-01', periods=100, freq='D')
series = pd.Series(data, index=dates)
# Tworzenie i dopasowanie modelu ARIMA
model = sm.tsa.ARIMA(series, order=(1, 1, 1))
results = model.fit()
# Podsumowanie wyników modelu
print(results.summary())
# Prognozowanie przyszłych wartości
forecast = results.forecast(steps=10)
print("Prognoza na 10 dni:", forecast)
# Wizualizacja
series.plot(label='Dane historyczne')
plt.plot(forecast, label='Prognoza', linestyle='--')
plt.legend()
plt.show()
SARIMAX Results
==============================================================================
Dep. Variable: y No. Observations: 100
Model: ARIMA(1, 1, 1) Log Likelihood -131.425
Date: Wed, 09 Oct 2024 AIC 268.850
Time: 14:36:46 BIC 276.635
Sample: 01-01-2023 HQIC 272.000
- 04-10-2023
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.3996 5.649 0.071 0.944 -10.672 11.471
ma.L1 -0.4156 5.591 -0.074 0.941 -11.374 10.543
sigma2 0.8329 0.123 6.780 0.000 0.592 1.074
===================================================================================
Ljung-Box (L1) (Q): 0.00 Jarque-Bera (JB): 0.53
Prob(Q): 0.95 Prob(JB): 0.77
Heteroskedasticity (H): 0.92 Skew: -0.16
Prob(H) (two-sided): 0.81 Kurtosis: 2.82
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Prognoza na 10 dni: 2023-04-11 39.618833
2023-04-12 39.620226
2023-04-13 39.620782
2023-04-14 39.621004
2023-04-15 39.621093
2023-04-16 39.621129
2023-04-17 39.621143
2023-04-18 39.621148
2023-04-19 39.621151
2023-04-20 39.621152
Freq: D, Name: predicted_mean, dtype: float64
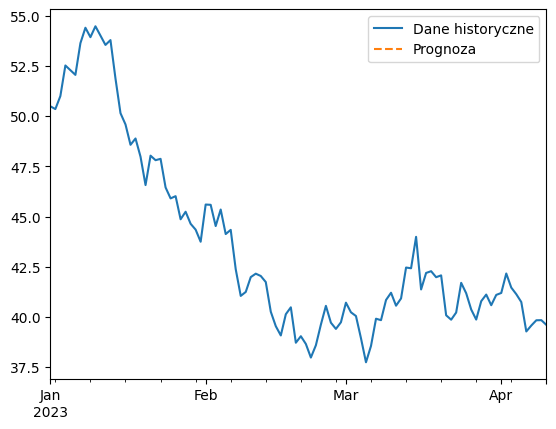
W tym przykładzie użyto Statsmodels do modelowania symulowanego szeregu czasowego za pomocą modelu ARIMA (ang. autoregressive integrated moving average). Model został dopasowany do danych, a następnie wykorzystany do prognozowania przyszłych wartości. Wyniki prognozy zostały zwizualizowane na wykresie, pokazując przewidywane wartości w stosunku do danych historycznych.
Przykład 2: Diagnostyka i wizualizacja reszt modelu ARIMA#
# Diagnostyka reszt modelu
residuals = results.resid
# Autokorelacja reszt
sm.graphics.tsa.plot_acf(residuals)
plt.show()
# Histogram reszt
residuals.plot(kind='hist', bins=30)
plt.title('Histogram reszt modelu')
plt.show()
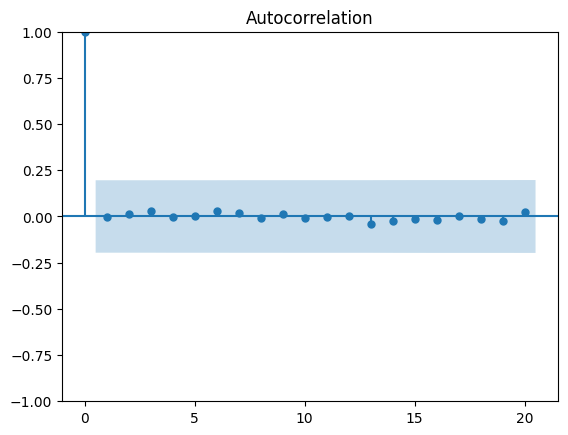
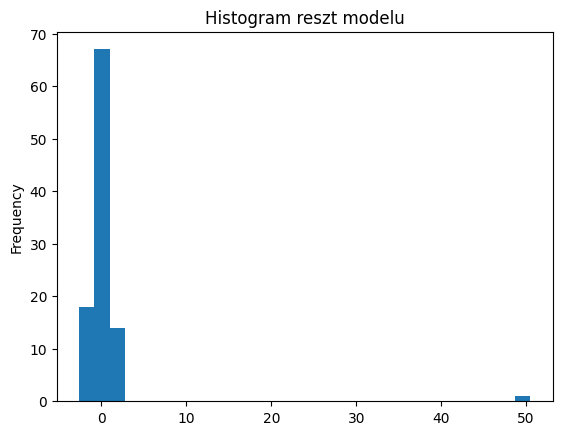
Powyższy kod pokazuje, jak przeprowadzić diagnostykę reszt modelu ARIMA. Analiza autokorelacji reszt pomaga ocenić, czy model dobrze dopasowuje się do danych, podczas gdy histogram reszt pozwala sprawdzić ich rozkład, co jest istotne dla oceny jakości modelu.
Statsforecast (Nixtlaverse)#
Statsforecast to nowoczesna biblioteka zaprojektowana do szybkiego i skalowalnego prognozowania szeregów czasowych. Należy do ekosystemu Nixtlaverse, który skupia narzędzia optymalizujące prognozowanie za pomocą różnych technik - od klasycznej analizy szeregów czasowych po metody ML. Statsforecast oferuje implementacje popularnych modeli, takich jak ETS, ARIMA, i inne, zoptymalizowane pod kątem szybkości i wydajności. Dzięki wykorzystaniu wielowątkowości i innych technik optymalizacji, Statsforecast pozwala na szybkie prognozowanie setek tysięcy szeregów czasowych jednocześnie.
Co więcej - w porównaniu do Statsforecast - dokumentacja i przewodniki Nixlaverse są znakomicie i przejrzyście napisane!!! Razem z pokrewnymi bibliotekami mlforecast i neural tworzą spójny ekosystem.
Zastosowania Statsforecast
Statsforecast jest używany do:
Prognozowania szeregów czasowych za pomocą modeli ARIMA, ETS, i innych.
Szybkiego i skalowalnego prognozowania wielu szeregów czasowych.
Dodatkowe materiały#
Przydatne linki - Statsforecast
Przykład 1: Szybkie prognozowanie szeregu czasowego za pomocą metody Holta-Wintersa#
from statsforecast import StatsForecast
from statsforecast.models import HoltWinters
import pandas as pd
# Przykładowe dane: air passengers
df = pd.read_csv('https://datasets-nixtla.s3.amazonaws.com/air-passengers.csv', parse_dates=['ds'])
# Tworzenie modelu Holta-Wintersa i prognozowanie
sf = StatsForecast(models=[HoltWinters(season_length=12)], freq='D')
# Uczenie modelu na podstawie historycznych danych
sf.fit(df=df)
# Prognozowanie przyszłych wartości
forecast_df = sf.predict(h=10, level=[90])
# Wyświetlanie prognozy
print(forecast_df)
# Wizualizacja prognozy
sf.plot(df.tail(5), forecast_df, level=[90])
/home/runner/.cache/pypoetry/virtualenvs/dsbook-K6kLFozp-py3.11/lib/python3.11/site-packages/statsforecast/core.py:492: FutureWarning:
In a future version the predictions will have the id as a column. You can set the `NIXTLA_ID_AS_COL` environment variable to adopt the new behavior and to suppress this warning.
/home/runner/.cache/pypoetry/virtualenvs/dsbook-K6kLFozp-py3.11/lib/python3.11/site-packages/statsforecast/core.py:1447: FutureWarning:
Passing the ids as the index is deprecated. Please provide them as a column instead.
ds HoltWinters HoltWinters-lo-90 HoltWinters-hi-90
unique_id
AirPassengers 1960-12-02 453.088745 428.115234 478.062256
AirPassengers 1960-12-03 427.476532 402.366119 452.586975
AirPassengers 1960-12-04 460.631775 435.381927 485.881622
AirPassengers 1960-12-05 497.036804 471.645081 522.428528
AirPassengers 1960-12-06 507.507538 481.971436 533.043640
AirPassengers 1960-12-07 567.922485 542.239502 593.605408
AirPassengers 1960-12-08 650.842590 625.010376 676.674866
AirPassengers 1960-12-09 635.878601 609.894531 661.862610
AirPassengers 1960-12-10 537.471191 511.332947 563.609497
AirPassengers 1960-12-11 488.687286 462.392334 514.982239

W powyższym przykładzie użyto Statsforecast do prognozowania szeregów czasowych przy użyciu modelu Holta-Wintersa. Wyniki prognozy zostały wyświetlone i zwizualizowane, pokazując prognozowane wartości na kolejne 10 dni.
Przykład 2: Szkolenie wielu modeli jednocześnie#
from statsforecast import StatsForecast
from statsforecast.models import HoltWinters, AutoARIMA, AutoETS
import pandas as pd
# Przykładowe dane: air passengers
df = pd.read_csv('https://datasets-nixtla.s3.amazonaws.com/air-passengers.csv', parse_dates=['ds'])
# Szkolenie kilku modeli jednocześnie
sf = StatsForecast(models=[
HoltWinters(season_length=12),
AutoARIMA(season_length=12),
AutoETS()], freq='D')
# Uczenie modelu na podstawie historycznych danych
sf.fit(df=df)
# Prognozowanie przyszłych wartości
forecast_df = sf.predict(h=12, level=[90])
# Wyświetlanie prognozy
print(forecast_df)
# Wizualizacja prognozy
sf.plot(df.tail(10), forecast_df, level=[90])
/home/runner/.cache/pypoetry/virtualenvs/dsbook-K6kLFozp-py3.11/lib/python3.11/site-packages/statsforecast/core.py:492: FutureWarning:
In a future version the predictions will have the id as a column. You can set the `NIXTLA_ID_AS_COL` environment variable to adopt the new behavior and to suppress this warning.
/home/runner/.cache/pypoetry/virtualenvs/dsbook-K6kLFozp-py3.11/lib/python3.11/site-packages/statsforecast/core.py:1447: FutureWarning:
Passing the ids as the index is deprecated. Please provide them as a column instead.
ds HoltWinters HoltWinters-lo-90 HoltWinters-hi-90 \
unique_id
AirPassengers 1960-12-02 453.088745 428.115234 478.062256
AirPassengers 1960-12-03 427.476532 402.366119 452.586975
AirPassengers 1960-12-04 460.631775 435.381927 485.881622
AirPassengers 1960-12-05 497.036804 471.645081 522.428528
AirPassengers 1960-12-06 507.507538 481.971436 533.043640
AirPassengers 1960-12-07 567.922485 542.239502 593.605408
AirPassengers 1960-12-08 650.842590 625.010376 676.674866
AirPassengers 1960-12-09 635.878601 609.894531 661.862610
AirPassengers 1960-12-10 537.471191 511.332947 563.609497
AirPassengers 1960-12-11 488.687286 462.392334 514.982239
AirPassengers 1960-12-12 420.511292 394.057220 446.965363
AirPassengers 1960-12-13 463.407196 436.791565 490.022827
AutoARIMA AutoARIMA-lo-90 AutoARIMA-hi-90 AutoETS \
unique_id
AirPassengers 444.300049 424.971436 463.628693 436.156677
AirPassengers 418.210022 394.616974 441.803070 440.317139
AirPassengers 446.237030 418.134003 474.340057 444.477600
AirPassengers 488.228943 456.491608 519.966248 448.638092
AirPassengers 499.231354 464.168854 534.293884 452.798553
AirPassengers 562.230652 524.150452 600.310852 456.959015
AirPassengers 649.230835 608.349976 690.111694 461.119476
AirPassengers 633.230774 589.730652 676.730896 465.279938
AirPassengers 535.230774 489.260010 581.201599 469.440399
AirPassengers 488.230804 439.915619 536.545959 473.600891
AirPassengers 417.230804 366.679810 467.781799 477.761353
AirPassengers 459.230804 406.538788 511.922821 481.921814
AutoETS-lo-90 AutoETS-hi-90
unique_id
AirPassengers 359.774292 512.539062
AirPassengers 331.475494 549.158813
AirPassengers 310.160889 578.794312
AirPassengers 292.366394 604.909790
AirPassengers 276.760742 628.836365
AirPassengers 262.666473 651.251587
AirPassengers 249.683929 672.555054
AirPassengers 237.554657 693.005249
AirPassengers 226.100342 712.780457
AirPassengers 215.192047 732.009705
AirPassengers 204.733047 750.789612
AirPassengers 194.648727 769.194885
